Pong Learn is now a browser lab for reinforcement learning. Instead of adding quiz questions to Pong, the project shows a paddle learning from experience while the interface explains what changed inside the policy.
The point is not to make Pong harder. The point is to make learning visible.
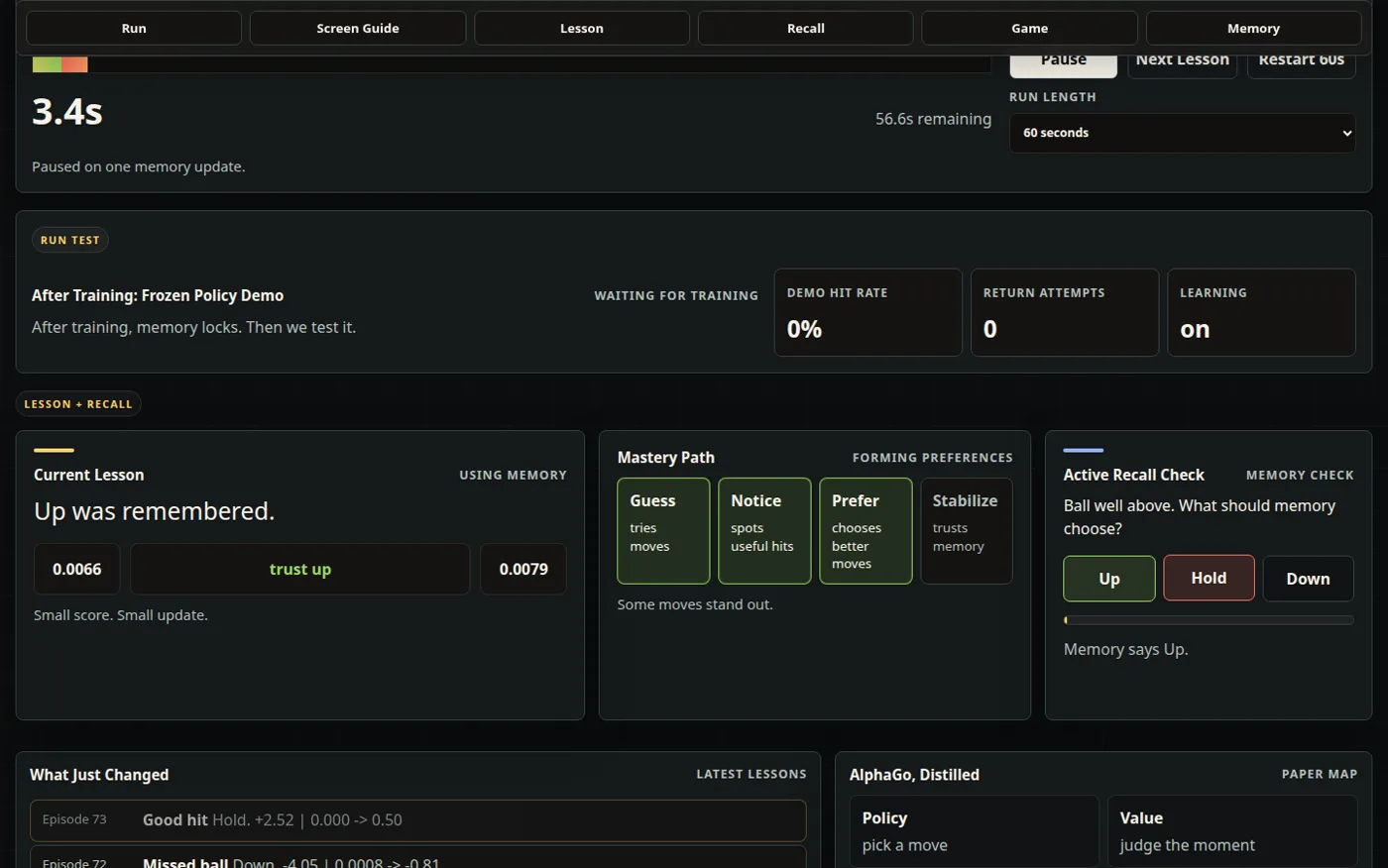
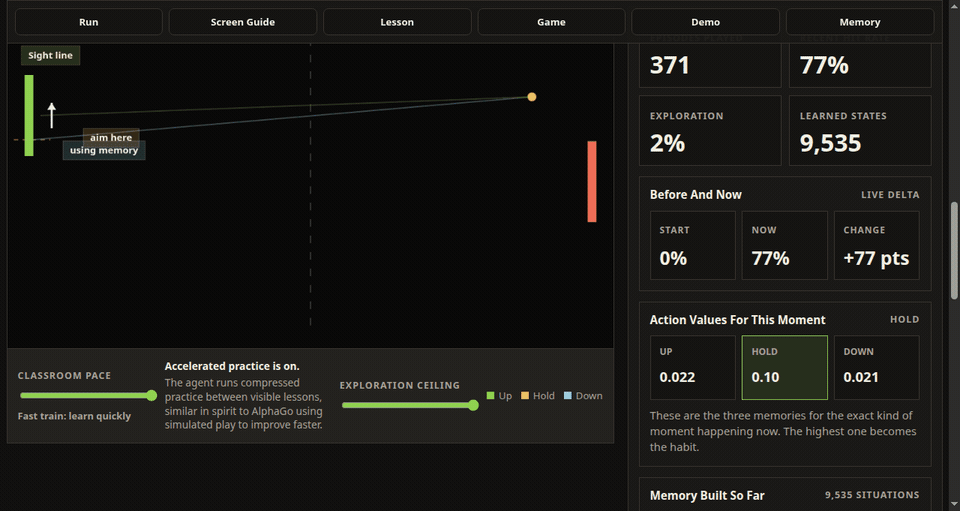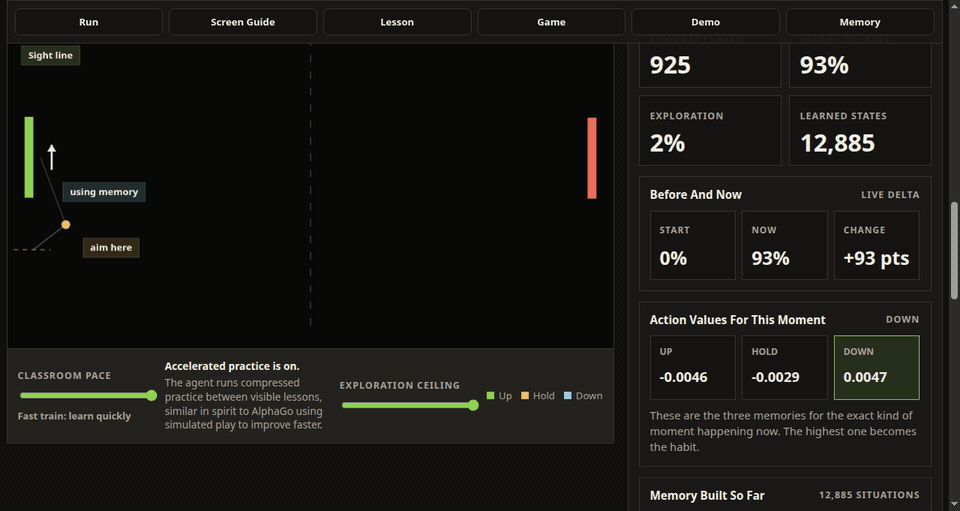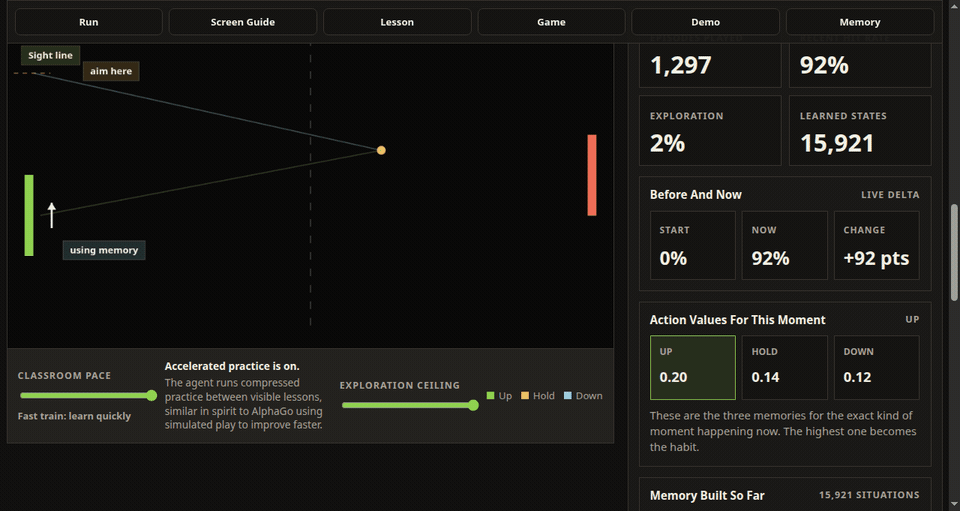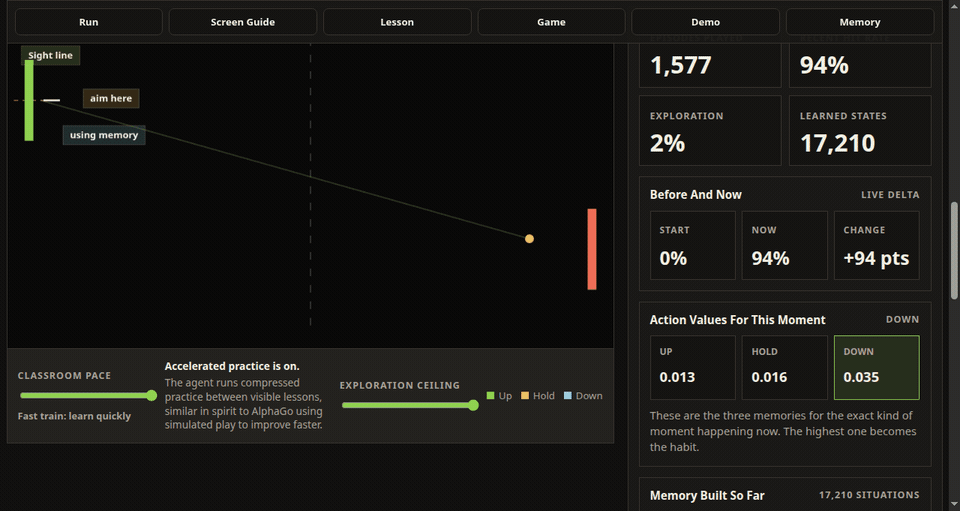
The left paddle is the learning agent. It observes a simplified game state, chooses up, hold, or down, receives a reward from the rally, and updates a stored action value. Over time, the hit rate, exploration level, learned states, memory tiles, Q-value cards, and policy map make that process visible.
The app starts with an educational walkthrough, then runs a timed training session. A viewer can choose a 30, 60, or 120 second run and watch the same loop repeat at a readable pace: observe the state, act, receive feedback, and update one remembered value.
Every rally becomes one small lesson: observe, act, receive reward, update memory, then test whether the policy makes sense.
The latest version adds an active recall check. Instead of only watching the dashboard, the viewer predicts whether memory should choose up, hold, or down, then compares that answer with the strongest visible Q-value. That small prompt turns the interface from passive observation into a retrieval-practice loop.
The training view also has a practical rhythm. The lesson card explains one reward update in plain language, the Next Lesson control jumps to the next useful feedback moment, accelerated practice compresses less interesting repetition, and the demo mode freezes learning so the user can see how the trained policy performs without more exploration.
PongLearn borrows the teaching principle from DeepMind-style reinforcement learning, then makes it small enough to inspect in a browser.
That framing matters because reinforcement learning is often explained with either abstract equations or finished demos. Pong Learn sits in the middle. It keeps the environment simple enough to understand while still showing the mechanics that make learning from reward work.
The project is inspired by the learning loop made famous by DeepMind's AlphaGo work: estimate useful actions, estimate future outcomes, improve from repeated experience, and then act from the improved policy. Pong Learn is not a recreation of AlphaGo. It uses tabular Q-learning instead of neural networks so the process is inspectable.